Codon models
Sometimes we may not be able to differentiate between the function or fitnesses of different codons encoding the same aminoacid, but still want to take into account the connectivity at the nucleotide level for visualizing the landscape as in a codon model of evolution. This way, we transform the actual landscape taking into account which transitions are allowed by a specific genetic code, how common they are and, in general, obtain a visualization that better reflects molecular evolution on a protein landscape.
Lets start this tutorial with a very simple artificial landscape: 1 aminoacids long protein sequence, where every aminoacid hads fitness 1 except Serine, that provides a fitness advantage of 2, as show in the following table
[1]:
# Import required libraries
import numpy as np
import logomaker as lm
import gpmap.plot.mpl as mplot
import gpmap.plot.ply as pplot
from gpmap.datasets import DataSet
from gpmap.space import SequenceSpace, CodonSpace
from gpmap.randwalk import WMWalk
from gpmap.seq import translate_seqs
1. Serine landscape
We can start by simply using the protein data to define a protein space
[2]:
protein_space = SequenceSpace(seq_length=1, alphabet_type='protein')
X = protein_space.genotypes
y = [2 if seq == "S" else 1 for seq in X]
protein_space = SequenceSpace(X=X, y=y, stop_y=0)
print(protein_space)
Sequence Space:
Type: protein
Sequence length: 1
Number of alleles per site: [21]
Genotypes: [A,C,D,...,W,Y,*]
Function y: [1.00,1.00,1.00,...,1.00,1.00,0.00]
Then, we can simply create the nucleotide space from this protein space with the to_nucleotide_space method, which naturally requires the space to be a protein space. By default, it associates the minimal function y to all of the sequences containing stop codons generated, but we can also specify a different value with the argument y_stop
[3]:
nc_space = protein_space.to_nucleotide_space(codon_table='Standard')
print(nc_space)
Sequence Space:
Type: dna
Sequence length: 3
Number of alleles per site: [4, 4, 4]
Genotypes: [AAA,AAC,AAG,...,TTC,TTG,TTT]
Function y: [1.00,1.00,1.00,...,1.00,1.00,1.00]
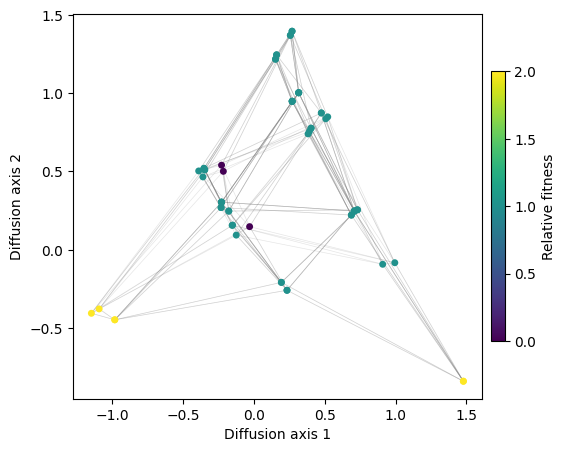
After making sure that the new space contains the encoding nucleotide sequences and the corresponding function associated to the encoded protein sequence, we can generate the visualization as before
[4]:
rw = WMWalk(nc_space)
rw.calc_visualization(mean_function=1.5)
[5]:
fig, axes = mplot.init_fig(1, 1, colsize=6, rowsize=5)
mplot.plot_visualization(axes, rw.nodes_df, edges_df=rw.space.get_edges_df(), x='1', y='2',
nodes_color='function', nodes_cmap_label='Relative fitness',
nodes_size=25, edges_alpha=0.2)
Using CodonSpace class
We also provide a more generic CodonSpace class that does this operation for us so that we only need to provide the aminoacid(s) are are going to be under selection, enabling also to visualizing the structure of the landscape corresponding to aminoacids with certain properties
[6]:
from gpmap.space import CodonSpace
[7]:
space = CodonSpace(allowed_aminoacids=['S'], codon_table='Standard', add_variation=True, seed=0)
print(space)
Sequence Space:
Type: dna
Sequence length: 3
Number of alleles per site: [4, 4, 4]
Genotypes: [AAA,AAC,AAG,...,TTC,TTG,TTT]
Function y: [1.18,1.04,1.10,...,0.96,0.92,0.83]
Note that we could also test how these landscapes would change under different genetic codes other than the standard. We use biopython module to translate the nucleotide sequence into protein sequence using NCBI reference for different codon tables or genetic codes
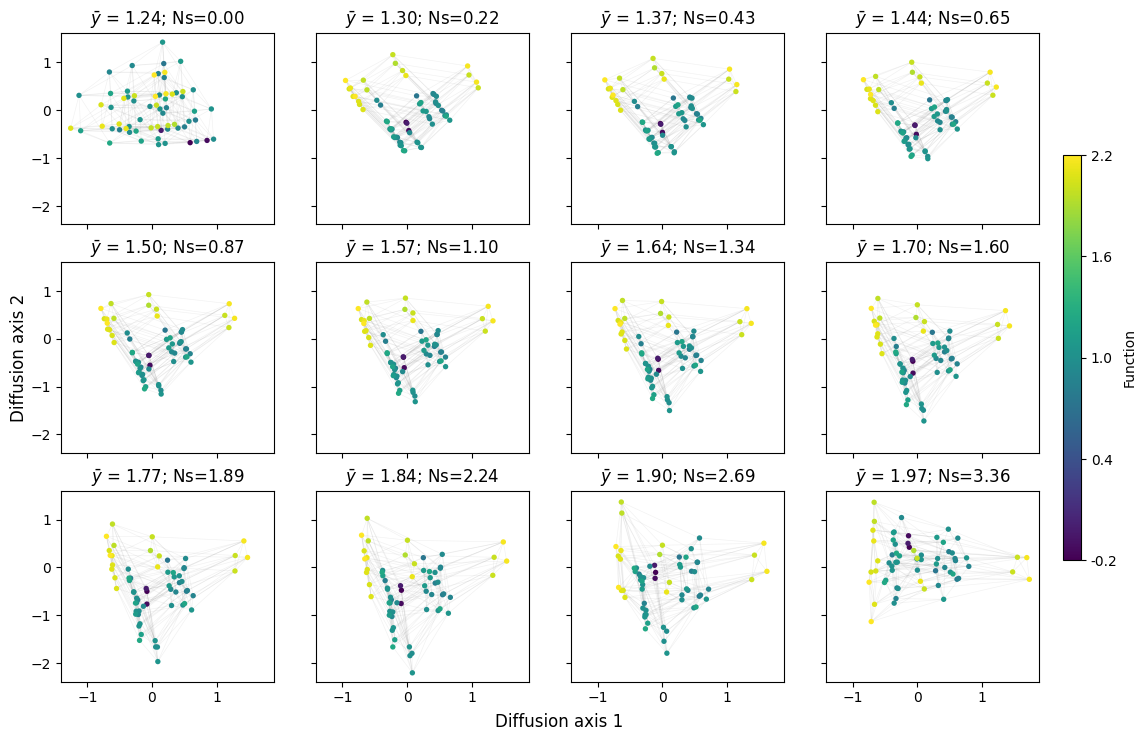
Other codon landscapes: hydrophobic and polar aminoacids
Thus, this class allows us to easily explore other basic codon landscapes by taking a certain category of aminoacids and seeing the generated structure. Lets say we are interested in non-aromatic hydrophobic aminoacids: A, V, I, L, M
[8]:
space = CodonSpace(allowed_aminoacids=['A', 'V', 'I', 'L', 'M'],
codon_table='Standard', add_variation=True, seed=0)
print(space)
Sequence Space:
Type: dna
Sequence length: 3
Number of alleles per site: [4, 4, 4]
Genotypes: [AAA,AAC,AAG,...,TTC,TTG,TTT]
Function y: [1.18,1.04,1.10,...,0.96,1.92,0.83]
[9]:
rw = WMWalk(space)
[10]:
mplot.figure_Ns_grid(rw, nodes_size=15)
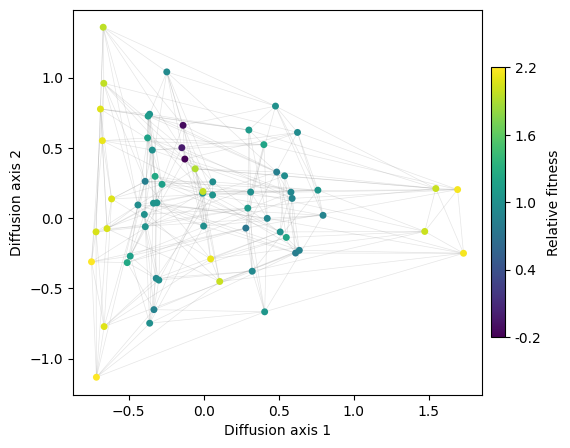
[11]:
rw.calc_visualization(mean_function=1.97)
nodes_df, edges_df = rw.nodes_df, rw.space.get_edges_df()
nodes_df['protein'] = translate_seqs(nodes_df.index)
[12]:
fig, axes = mplot.init_fig(1, 1, colsize=6, rowsize=5)
mplot.plot_visualization(axes, nodes_df, edges_df=edges_df, x='1', y='2',
nodes_color='function', nodes_cmap_label='Relative fitness',
nodes_size=25, edges_alpha=0.2)
[13]:
fig = pplot.plot_visualization(nodes_df, edges_df=edges_df, text=nodes_df['protein'], nodes_size=8)
fig.show('notebook')
We can see that diffusion axis 1 separates mainly codons encoding A from those encoding L,I and M, which are isolated by the genetic code, and only connected through V. Interestingly, diffusion axis 2 sorts L, I and M in a very particular way from top to bottom: we have the set of 2 codons encoding for L followed by the set of 4 codons encoding for I and M, followed now by the set of 4 codons encoding for L. However, as these are all equally connected to each other, it is likely that the ordering is driven by the random variability in fitness that we introduced to be able to separate genotypes better
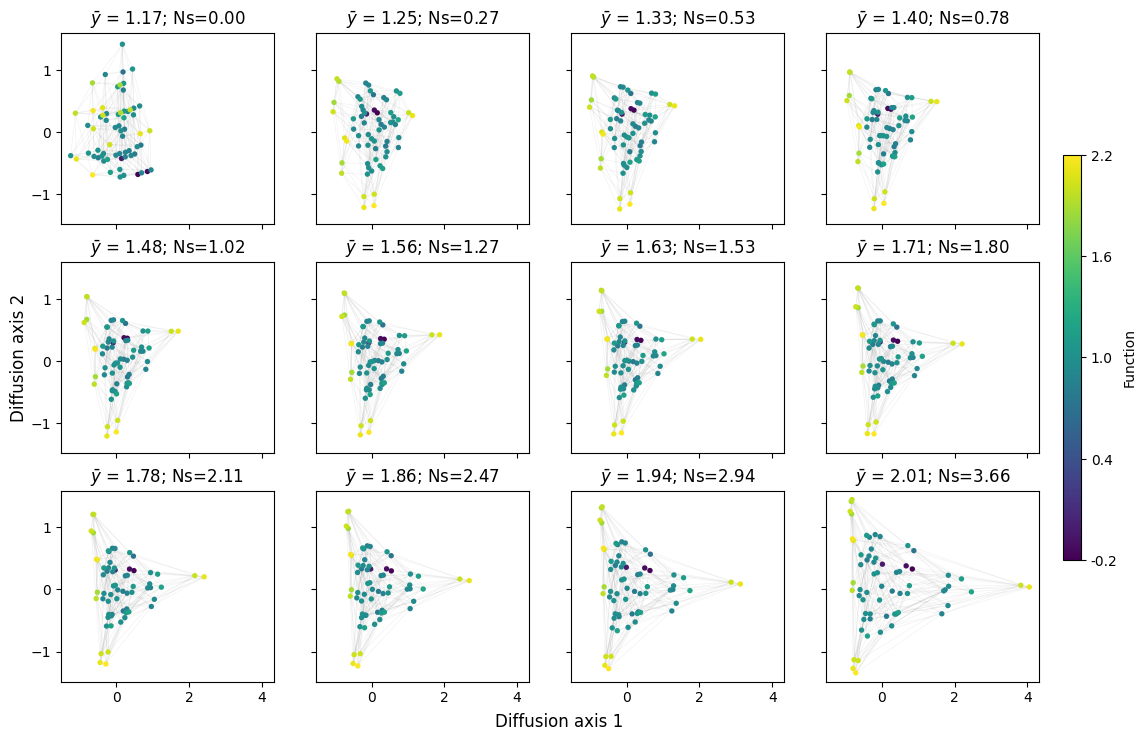
Lets look at the polar aminoacids now:
[14]:
space = CodonSpace(allowed_aminoacids=['S', 'T', 'N', 'Q'],
codon_table='Standard', add_variation=True, seed=0)
rw = WMWalk(space)
mplot.figure_Ns_grid(rw, nodes_size=15)
[15]:
rw.calc_visualization(mean_function=1.95)
nodes_df, edges_df = rw.nodes_df, rw.space.get_edges_df()
nodes_df['protein'] = translate_seqs(nodes_df.index)
fig, axes = mplot.init_fig(1, 1, colsize=6, rowsize=5)
mplot.plot_visualization(axes, nodes_df, edges_df=edges_df, x='1', y='2',
nodes_color='function', nodes_cmap_label='Relative fitness',
nodes_size=25, edges_alpha=0.2)
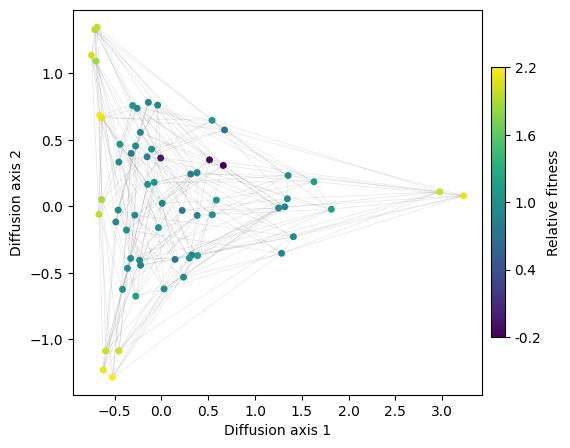
[16]:
fig = pplot.plot_visualization(nodes_df, edges_df=edges_df, text=nodes_df['protein'], nodes_size=8)
fig.show('notebook')
2. GB1 landscape
Once we have looked at how to work with very simple examples, we can move to a more realistic experimental binding landscape that we have previously visualized in the protein space: the GB1 landscape.
First, to reduce the computational complexity for this tutorial, we are going to use a reduced set of genotypes at the protein sequence to accelerate calculations. Previous results and visualizations suggests that the second site are mostly neutral. Thus, we are going to generate a modified landscape by marginalizing or averaging out the second position
[17]:
gb1 = DataSet('gb1')
gb1.landscape['3aa'] = [x[0] + x[2:] for x in gb1.landscape.index]
df = gb1.landscape.groupby("3aa").mean()
df.head()
[17]:
| y | |
|---|---|
| 3aa | |
| AAA | -0.232895 |
| AAC | -3.024491 |
| AAD | -3.095838 |
| AAE | -4.628683 |
| AAF | -3.618632 |
Then, we can transform our protein space into a nucleotide space easily using the standard genetic code for translation
[18]:
prot_space = SequenceSpace(X=df.index.values, y=df['y'].values, stop_y=df['y'].min())
nc_space = prot_space.to_nucleotide_space(codon_table='Standard')
print(nc_space)
Sequence Space:
Type: dna
Sequence length: 9
Number of alleles per site: [4, 4, 4, 4, 4, 4, 4, 4, 4]
Genotypes: [AAAAAAAAA,AAAAAAAAC,AAAAAAAAG,...,TTTTTTTTC,TTTTTTTTG,TTTTTTTTT]
Function y: [-5.10,-5.27,-5.10,...,-4.67,-4.35,-4.67]
And calculate the visualization coordinates in this new space
[19]:
rw = WMWalk(nc_space)
rw.calc_visualization(mean_function=0)
nodes_df, edges_df = rw.nodes_df, rw.space.get_edges_df()
nodes_df['protein'] = translate_seqs(nodes_df.index)
nodes_df.head()
[19]:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | function | stationary_freq | protein | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AAAAAAAAA | 0.126679 | 0.837879 | 0.165008 | 0.372440 | 0.665481 | 0.154989 | 0.176266 | 1.309424 | 2.938940 | 2.845559 | -5.103351 | 1.623564e-07 | KKK |
| AAAAAAAAC | 0.127629 | 0.761920 | 0.166234 | 0.251658 | 0.627007 | -0.032821 | 0.200446 | 1.240071 | 2.826776 | 2.794200 | -5.267316 | 1.339295e-07 | KKN |
| AAAAAAAAG | 0.142071 | 0.863665 | 0.170276 | 0.359610 | 0.664400 | 0.164817 | 0.178973 | 1.299232 | 2.924533 | 2.825219 | -5.103351 | 1.623564e-07 | KKK |
| AAAAAAAAT | 0.127629 | 0.761920 | 0.166234 | 0.251658 | 0.627007 | -0.032821 | 0.200446 | 1.240071 | 2.826776 | 2.794200 | -5.267316 | 1.339295e-07 | KKN |
| AAAAAAACA | -0.006032 | 0.610716 | 0.045477 | 0.688990 | 0.665612 | 0.091810 | 0.079757 | 0.949192 | 1.900243 | 1.594865 | -5.663853 | 8.408390e-08 | KKT |
[20]:
fig, axes = mplot.init_fig(1, 1, figsize=(11, 10))
mplot.plot_visualization(axes, nodes_df, edges_df=edges_df,
edges_alpha=0.005,
sort_by='3', sort_ascending=True,
nodes_size=10, x='1', y='2')
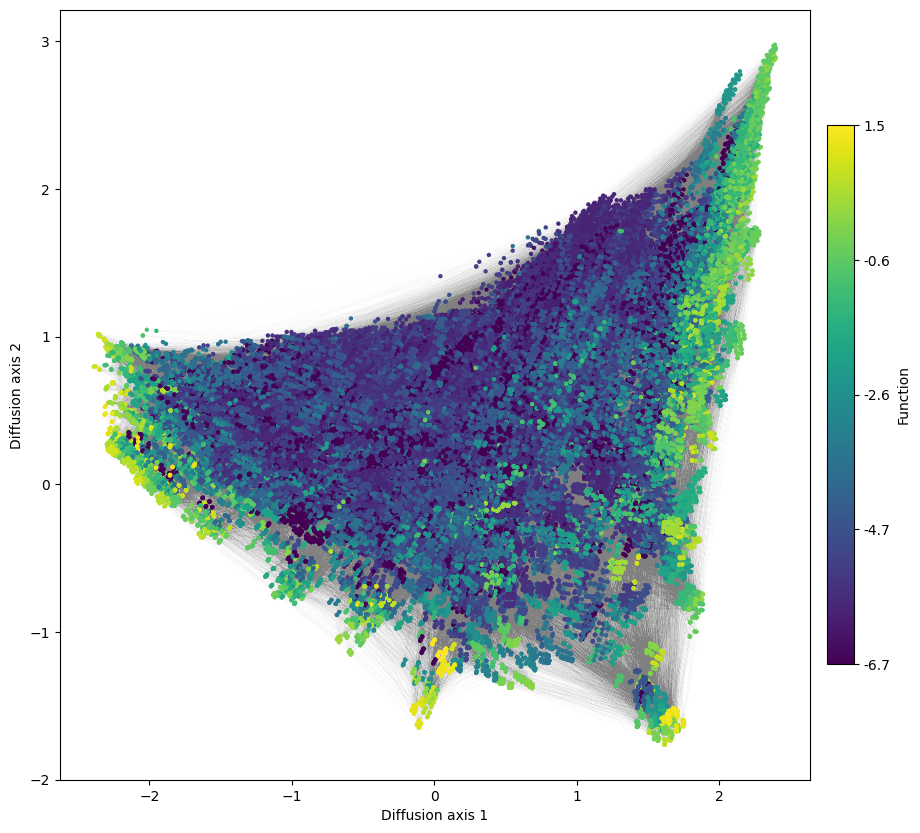
We can still see mainly three fitness peaks as before, but the connectivity between them seems to be changed compared with the protein landscape, e.g. two of them do not seem to have any high fitness intermediate. That can be caused by aminoacid transitions not really being allowed under the genetic code. This imposes strong constraints in the order in which aminoacid substitutions need to take place within a viable set of aminoacids, as we saw in our simple examples of landscapes for different aminoacid types.
However, are the peaks the same?
[21]:
labels = ['39', '41', '54']
peak_seqs = [nodes_df.loc[nodes_df['2'] > 2.5, 'protein'],
nodes_df.loc[nodes_df['1'] < -2, 'protein'],
nodes_df.loc[np.logical_and(nodes_df['2'] < -1.2, nodes_df['1'] > 1.2), 'protein']]
fig, subplots = mplot.init_fig(1, 3, colsize=4, rowsize=2)
for i, (seqs, axes) in enumerate(zip(peak_seqs, subplots)):
m = lm.alignment_to_matrix(seqs.values, to_type='probability', pseudocount=0)
m.index = np.arange(m.shape[0])
logo = lm.Logo(m, ax=axes, color_scheme='chemistry', vpad=0.05)
axes.set(ylabel='Probability', xlabel='Position',
xticks=np.arange(m.shape[0]),
xticklabels=labels, title='Region {}'.format(i+1))
fig.tight_layout()
Warning: Character '*' is not in color_dict. Using black.
Warning: Character '*' is not in color_dict. Using black.

The peaks now have some feature in common with the ones derived from the protein space, but they appear more constrained: - Region 1: While previous peak characterized by G at position 41 could contain almost every aminoacid at position 54, we can see now that at the very peak, L is strongly represented. This is in part because the peak is now spread out into a larger streak and where aminoacid substitutions are ordered according to the genetic code, but also to the fact that L is encoded by 6 codons, while other aminoacids can be encoded up to only 1, such as M, which still retains a relatively large frequency at position 54. - Region 2: previously dominated by FG, LG sequences at positions 41 and 54, it now contains mostly LG, LT, LA. - Region 3: instead of containing CA and AA at 41,54, we can now see mostly AA. This is because A to C transition can no longer take place with a single substitution but require at least 2. S is also allowed at position 41 together with 54A, but the genetic code only allows it to change to C and not A with a single nucleotide change, pushing it appart form AA. On the other hand, G, which is allowed at 54 together with 41A is accessible from A, pulling AA and AG together in the same peak.
Another key difference is that XGG is no longer a viable infermediate between regions 1 and 2, because nor L or F at position 41 can change to G in a single mutation.