Experimental data
In contrast to theoretical or computational landscapes, like the Serine codon model shown in previous sections, empirical landscapes are based on experimental data. Such data is typically noisy and incomplete, so we need to apply additional methods to obtain reliable estimates of the phenotype of every possible genotype in order to visualize the genotype-phenotype map. In this section, we will illustrate the two methods available in gpmap-tools for inference of complete genotype-phenotype
maps \(f\) from noisy measurements y at a subset of sequences X. Optionally, the variance associated to the measurement y_var can be provided.
Note: these methods only work for sequences of the same length
Minimum epistasis interpolation (MEI) finds the genotype-phenotype map that minimizes the sum of squared P-th epistatic coefficients \(\bar{\epsilon_P^2}\) while exactly matching the data
yat sequencesX(read more).Empirical VC regression estimates a prior distribution characterized by the variance explained by interactions of every possible order from the empirical distance-correlation function computed from the available data. Then, it uses this prior distribution to perform Gaussian process regression to infer a complete genotype-phenotype map (read more).
In this section, we will illustrate how to use these methods using simulated and real data and how to use them to evaluate the evidence supporting specific hypotheses about the genotype-phenotype map.
[ ]:
# Import required libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from itertools import product, combinations
from scipy.stats import pearsonr, norm
from gpmap.datasets import DataSet
from gpmap.inference import VCregression, MinimumEpistasisInterpolator
from gpmap.plot.mpl import init_fig
Inference from simulated data
We first illustrate how to use these methods using simulated data. In this case, we know what the true genotype-phenotype map is and can compare the model inferences with the real values.
How to sample functions from the prior distribution
We will simulate data from the Variance Component regression model. In order to do so, we need to define the configuration of sequence space, the variance associated to interactions of every possible order lambdas, standard deviation of the measurement noise sigma and the fraction of genotypes that are not measured in the experiment p_missing.
[2]:
np.random.seed(0)
lambdas_true = np.array([1e4, 1e3, 2e2, 1e0, 1e-1, 3e-3, 1e-5])
model = VCregression(seq_length=6, alphabet_type='dna', lambdas=lambdas_true)
f, X, y, y_var = model.simulate(y_var=0.04, p_missing=0.1)
idx = model.get_obs_idx(X)
X_test = np.delete(model.genotypes, idx)
f_test = np.delete(f, idx)
data = pd.DataFrame({'y': y, 'y_var': y_var, 'f': f[idx]}, index=X)
data
[2]:
| y | y_var | f | |
|---|---|---|---|
| AAAAAA | 0.640632 | 0.04 | 0.496707 |
| AAAAAC | -2.314924 | 0.04 | -2.381059 |
| AAAAAG | -2.150190 | 0.04 | -2.072592 |
| AAAAAT | 1.466791 | 0.04 | 1.143917 |
| AAAACA | 3.854757 | 0.04 | 4.207335 |
| ... | ... | ... | ... |
| TTTTGG | 0.791477 | 0.04 | 0.805718 |
| TTTTGT | 1.621376 | 0.04 | 1.522178 |
| TTTTTA | 3.755850 | 0.04 | 3.650933 |
| TTTTTC | 1.187770 | 0.04 | 1.162799 |
| TTTTTG | 3.084332 | 0.04 | 2.627240 |
3693 rows × 3 columns
How to compute the minimum epistasis interpolation solution
This can be done very simply by defining a MinimumEpistasisInterpolator object with the right configuration of sequence space and the order of local epistatic coefficients we aim to penalize. In this case, we set P=2 to minimize the sum of squared epistatic coefficients.
[3]:
model = MinimumEpistasisInterpolator(P=2, seq_length=6, alphabet_type='dna')
model.set_data(X=X, y=y)
mei = model.predict()
mei
[3]:
| f | |
|---|---|
| AAAAAA | 0.640632 |
| AAAAAC | -2.314924 |
| AAAAAG | -2.150190 |
| AAAAAT | 1.466791 |
| AAAACA | 3.854757 |
| ... | ... |
| TTTTGT | 1.621376 |
| TTTTTA | 3.755850 |
| TTTTTC | 1.187770 |
| TTTTTG | 3.084332 |
| TTTTTT | 3.728994 |
4096 rows × 1 columns
We can now compare the predicted with the true phenotype at the held-out test sequences
[4]:
r2 = pearsonr(mei['f'], f)[0] ** 2
fig, axes = plt.subplots(1, 1, figsize=(4, 4))
axes.scatter(x=mei['f'], y=f, c='black', alpha=0.5, s=5, lw=0)
ticks = np.arange(-10, 9, 2)
axes.axline((0, 0), (1, 1), lw=0.75, linestyle='--', c='grey')
axes.set(xlabel=r'$y_{True}$', ylabel=r'$y_{pred}$', aspect='equal', xlim=(-15, 10), ylim=(-15, 10))
axes.text(0.03, 0.97, r'$R^2$=' + '{:.3f}'.format(r2), transform=axes.transAxes,
va='top')
[4]:
Text(0.03, 0.97, '$R^2$=0.995')
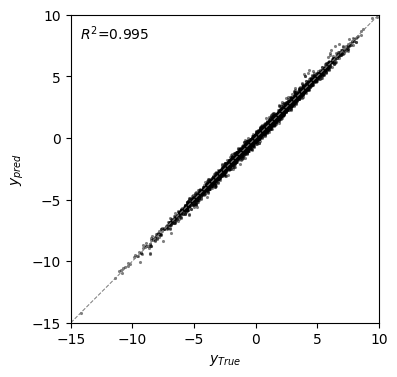
This comparison shows a very high correlation between the predictions and the real phenotypic values, but the extremely low and high values tend to be over and underestimated, respectively.
How to estimate Variance Components \(\lambda\)’s
We next illustrate how to use Variance Component regression on the same simulated data for comparison. The first step is the estimation of the variance components from the data. The covariance matrix \(K\) under the prior is given by
We define the \(\lambda_k\) through kernel alignment. This is achieved by finding the non-negative linear combination of the covariance matrices \(K_k\) associated to each pure interactions of order \(k\) that that minimize the Frobenius norm of the difference with the empirical second moment matrix \((y - \bar y)^T(y - \bar y)\)
[5]:
model = VCregression(seq_length=6, alphabet_type="dna")
model.fit(X, y, y_var)
vc = model.lambdas_to_variance(model.lambdas)
vc_p = vc / vc.sum() * 100
[6]:
k = np.arange(model.lambdas.shape[0])
fig, subplots = plt.subplots(1, 3, figsize=(12, 3.5))
axes = subplots[0]
axes.bar(x=k, height=model.lambdas, color='black')
axes.set(xlabel='k', ylabel=r'$\lambda_k$', yscale='log',
xticks=np.arange(7))
axes = subplots[1]
axes.bar(x=k[1:], height=vc_p, color='black')
axes.set(xlabel='k', ylabel='% variance explained')
axes = subplots[2]
axes.scatter(lambdas_true, model.lambdas, c='black')
lims = (1e-5, 1e6)
axes.plot(lims, lims, c='grey', lw=0.3, alpha=0.5)
axes.set(xscale='log', yscale='log',
xlabel=r'True $\lambda_k$',
ylabel=r'Inferred $\lambda_k$',
xlim=lims, ylim=lims)
fig.tight_layout()
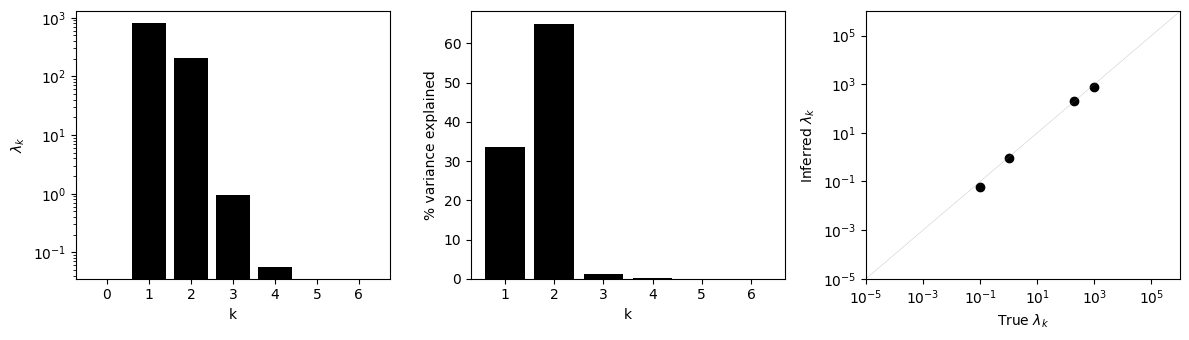
We can see that the inferred variance components are very similar in log scale to the true data-generating parameters.
However, when data is sparse, kernel alignment is a hard problem and we need to regularize towards simpler solutions. While we could shrink towards additivity, another good general choice that still models high order interactions is towards exponential decay of the variance components. We can do it by setting cross_validation=True and penalizing the second order moments of the \(\log \lambda_k\) as a function of \(k\). It will automatically split the data into different folds and
perform kernel alignment under different regularization strength to find the penalization constant that best generalizes to the validation set according to a metric. These metrics can be the Frobenius of the difference between the prior and second moment matrix, \(R^2\) on the or the log-likelihood of the predictions on the validation set. This can be specified through the argument cv_loss_function='r2' ,cv_loss_function='logL'.
How to obtain phenotypic predictions under a VC prior
Once we know the parameters of the Variance Component prior, we can compute the posterior distribution for the complete genotype-phenotype map with the method predict
[7]:
model.fit(X, y, y_var)
pred = model.predict()
pred
[7]:
| f | |
|---|---|
| AAAAAA | 0.509161 |
| AAAAAC | -2.099185 |
| AAAAAG | -2.021162 |
| AAAAAT | 1.261439 |
| AAAACA | 3.904009 |
| ... | ... |
| TTTTGT | 1.799622 |
| TTTTTA | 3.642860 |
| TTTTTC | 1.275835 |
| TTTTTG | 2.718211 |
| TTTTTT | 4.253923 |
4096 rows × 1 columns
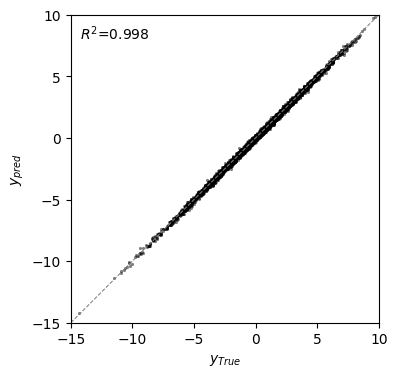
We can now compare the predictions with the true phenotypic values in held-out sequences, achieving better predictive performance than with MEI.
[8]:
r2 = pearsonr(pred["f"], f)[0] ** 2
fig, axes = plt.subplots(1, 1, figsize=(4, 4))
axes.scatter(x=pred["f"], y=f, c="black", alpha=0.5, s=5, lw=0)
ticks = np.arange(-10, 9, 2)
axes.axline((0, 0), (1, 1), lw=0.75, linestyle="--", c="grey")
axes.set(
xlabel=r"$y_{True}$",
ylabel=r"$y_{pred}$",
aspect="equal",
xlim=(-15, 10),
ylim=(-15, 10),
)
axes.text(
0.03,
0.97,
r"$R^2$=" + "{:.3f}".format(r2),
transform=axes.transAxes,
va="top",
)
[8]:
Text(0.03, 0.97, '$R^2$=0.998')
How to calculate uncertainty of the predictions
In the previous section, we have shown how to compute the posterior mean of the complete genotype-phenotype given the data and the estimated variance components. However, in cases where the ground truth is not known, it can be useful to have an idea about the uncertainty of the phenotypic predictions for new sequences. As we are using Gaussian process models with Gaussian likelihood function, we can compute, not only the posterior mean, but also the posterior variance and 95% probability
credible interval for these sequences by setting calc_variance=True.
Note: Computing the variance for every possible sequence is usually unfeasible because we need to solve a system of \(~\alpha^\ell\) equations for computing the variance of each sequence. Thus, in practice, this calculation can only be done for a small subset of sequences of interest.
[9]:
pred = model.predict(X_test, calc_variance=True)
pred['f'] = f[model.likelihood.idx[X_test]]
pred
100%|██████████| 403/403 [00:16<00:00, 24.33it/s]
[9]:
| f | f_var | f_std | ci_95_lower | ci_95_upper | |
|---|---|---|---|---|---|
| AAAACG | -1.661166 | 0.022802 | 0.151005 | -2.026398 | -1.422378 |
| AAAACT | 1.739073 | 0.021753 | 0.147488 | 1.361176 | 1.951128 |
| AAAAGA | 1.857192 | 0.021762 | 0.147520 | 1.439720 | 2.029800 |
| AAACGG | -5.395939 | 0.020771 | 0.144121 | -5.487868 | -4.911382 |
| AAAGAT | 1.554774 | 0.022872 | 0.151234 | 1.277205 | 1.882139 |
| ... | ... | ... | ... | ... | ... |
| TTTGCC | -8.340758 | 0.021756 | 0.147500 | -8.462849 | -7.872850 |
| TTTGCG | -4.501158 | 0.021703 | 0.147320 | -4.511932 | -3.922653 |
| TTTGTA | -3.320864 | 0.020772 | 0.144126 | -3.539676 | -2.963171 |
| TTTTCA | 5.393270 | 0.020795 | 0.144206 | 4.917685 | 5.494508 |
| TTTTTT | 4.110144 | 0.025390 | 0.159342 | 3.935240 | 4.572607 |
403 rows × 5 columns
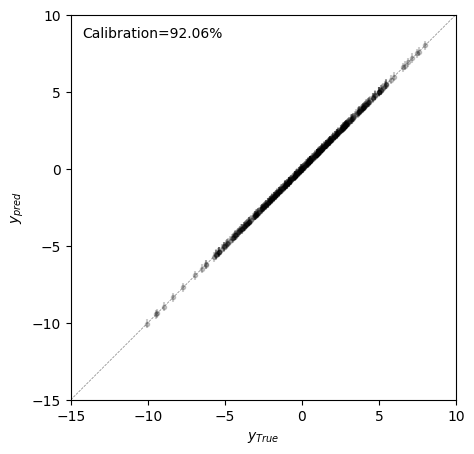
We can now check that predictions are well calibrated, this is, that the true value lies withing the 95% probability predicted interval close to the expected 95% probability; and show the error bars in the scatterplot to visualize if uncertainty is uniformly distributed along the whole range of true phenotypic values.
[10]:
perc = np.mean((f_test > pred['ci_95_lower']) & (f_test < pred['ci_95_upper'])) * 100
fig, axes = plt.subplots(1, 1, figsize=(5, 5))
axes.errorbar(
x=f_test,
y=pred["f"],
yerr=2 * pred["f_std"],
c="black",
markersize=3,
fmt="o",
alpha=0.2,
)
axes.axline((0, 0), (1, 1), lw=0.5, c='grey', linestyle='--')
axes.set(
xlabel=r"$y_{True}$",
ylabel=r"$y_{pred}$",
aspect=1,
xlim=(-15, 10),
ylim=(-15, 10),
)
axes.text(0.03, 0.97, 'Calibration={:.2f}%'.format(perc), transform=axes.transAxes, va='top')
[10]:
Text(0.03, 0.97, 'Calibration=92.06%')
How to estimate mutational effects and epistatic coefficients under the prior
Because the posterior distribution of the sequence function relationship is also a multivariate gaussian,
We can easily compute the posterior for any linear combination represented by \(B\) of a multivariate normal distribution
Without any prior distribution, we can assume that \(\Sigma=D_{\sigma^2}\) and \(\mu=y\), and use the following function to compute the posterior distribution for specific linear combinations given by the contrast matrix \(B\)
[11]:
def make_contrasts(df, contrast_matrix):
f = df['y']
Sigma = np.diag(df['y_var'])
B = contrast_matrix.T.values
mu = B @ f
std = np.sqrt(np.diag(B @ Sigma @ B.T))
posterior = norm(mu, std)
p = posterior.cdf(0.)
p = np.max(np.vstack([p, 1-p]), axis=0)
contrasts = pd.DataFrame({'estimate': mu, 'std': std,
'ci_95_lower': mu - 2 * std,
'ci_95_upper': mu + 2 * std,
'p(|x|>0)': p},
index=contrast_matrix.columns)
return(contrasts)
Lets start by estimating mutational effects fromTTTTTT to TTTTTC:
[12]:
seqs = ['TTTTTA', 'TTTTTC']
df = data.loc[seqs, :]
df
[12]:
| y | y_var | f | |
|---|---|---|---|
| TTTTTA | 3.75585 | 0.04 | 3.650933 |
| TTTTTC | 1.18777 | 0.04 | 1.162799 |
[13]:
contrast_matrix = pd.DataFrame({'A6C': [1, -1]}, index=['TTTTTA', 'TTTTTC'])
contrast_matrix
[13]:
| A6C | |
|---|---|
| TTTTTA | 1 |
| TTTTTC | -1 |
Lets start by computing the true mutational effect from the simulated genotype-phenotype map
[14]:
true_effect = (contrast_matrix.T.values @ df['f'].values)[0]
print('True mutational effect = {:.2f}'.format(true_effect))
True mutational effect = 2.49
and compare it with our naive posterior estimate.
[15]:
contrasts = make_contrasts(df, contrast_matrix)
mu = contrasts.loc['A6C', 'estimate']
lower = contrasts.loc['A6C', 'ci_95_lower']
upper = contrasts.loc['A6C', 'ci_95_upper']
print('Estimated mutational effect = {:.2f} (95% CI = [{:.2f}, {:2f}])'.format(mu, lower, upper))
Estimated mutational effect = 2.57 (95% CI = [2.00, 3.133766])
We can see that the true effect is relatively close to the inferred one, and is within the 95% credible interval. However, the 95% credible interval is quite wide. Thus, can we do better by including taking into account our prior distribution?
We can do the same calculations using the make_contrast method provided any user-defined contrast_matrix
[16]:
contrasts = model.make_contrasts(contrast_matrix=contrast_matrix)
mu = contrasts.loc['A6C', 'estimate']
lower = contrasts.loc['A6C', 'ci_95_lower']
upper = contrasts.loc['A6C', 'ci_95_upper']
print('Estimated mutational effect with GP prior = {:.2f} (95% CI = [{:.2f}, {:2f}])'.format(mu, lower, upper))
100%|██████████| 2/2 [00:00<00:00, 18.83it/s]
Estimated mutational effect with GP prior = 2.37 (95% CI = [2.06, 2.672019])
Thus, we can see how the estimate now is closer to the true simulated mutational effect and that the posterior distribution is tighter around it, illustrating that we have less uncertainty about its effect when taking into account the observed mutational effects across all genetic backgrounds appropriately.
We can do these analyses not only for mutational effects, but also for epistatic coefficients of any order. Lets see how the previous mutational effect changes when we add a T0A mutation at the first position:
[17]:
seqs = ['TTTTTA', 'TTTTTC', 'ATTTTA', 'ATTTTC']
df = data.loc[seqs, :]
df
[17]:
| y | y_var | f | |
|---|---|---|---|
| TTTTTA | 3.755850 | 0.04 | 3.650933 |
| TTTTTC | 1.187770 | 0.04 | 1.162799 |
| ATTTTA | 2.589606 | 0.04 | 2.611931 |
| ATTTTC | 2.904488 | 0.04 | 2.793064 |
Lets do it again first without using our prior distribution
[18]:
contrast_matrix = pd.DataFrame({'epistatic_coeff': [1, -1, -1, 1]},
index=seqs)
contrast_matrix
[18]:
| epistatic_coeff | |
|---|---|
| TTTTTA | 1 |
| TTTTTC | -1 |
| ATTTTA | -1 |
| ATTTTC | 1 |
[19]:
true_effect = (contrast_matrix.T.values @ df['f'].values)[0]
print('True epistatic coefficient = {:.2f}'.format(true_effect))
True epistatic coefficient = 2.67
[20]:
contrasts = make_contrasts(df, contrast_matrix)
mu = contrasts.loc['epistatic_coeff', 'estimate']
lower = contrasts.loc['epistatic_coeff', 'ci_95_lower']
upper = contrasts.loc['epistatic_coeff', 'ci_95_upper']
print('Estimated epistatic coefficient = {:.2f} (95% CI = [{:.2f}, {:2f}])'.format(mu, lower, upper))
Estimated epistatic coefficient = 2.88 (95% CI = [2.08, 3.682962])
[21]:
contrasts = model.make_contrasts(contrast_matrix=contrast_matrix)
mu = contrasts.loc['epistatic_coeff', 'estimate']
lower = contrasts.loc['epistatic_coeff', 'ci_95_lower']
upper = contrasts.loc['epistatic_coeff', 'ci_95_upper']
print('Estimated epistatic coefficient with GP prior = {:.2f} (95% CI = [{:.2f}, {:2f}])'.format(mu, lower, upper))
100%|██████████| 2/2 [00:00<00:00, 14.18it/s]
Estimated epistatic coefficient with GP prior = 2.46 (95% CI = [2.11, 2.806350])
Again, we see how incorporation the prior knowledge about how well mutational effects generalize across genetic backgrounds provides a better estimate of the true epistatic coefficient and a tighter credible interval around it.
Inference from real data: protein GB1
In the next section, we are going to infer the complete combinatorial landscape of the protein G domain B1 from experimental data [Wu et. al (2016)]. In this study, a library containing nearly all possible aminoacid combinations at positions 39, 40, 41 and 54 was selected for binding to the constant fraction of IgG using an mRNA display approach. Thus, by sequencing the mRNA library before and after selection, we can obtain estimates of how strongly each sequence in the library binds its target.
Data preprocessing
We take the number of times a sequence is observed in the input and selected samples as raw data for our purposes as provided by the authors here.
[22]:
gb1 = DataSet('gb1')
counts = gb1.raw_data
counts
[22]:
| input | selected | |
|---|---|---|
| sequence | ||
| VDGV | 92735 | 338346 |
| ADGV | 34 | 43 |
| CDGV | 850 | 641 |
| DDGV | 63 | 63 |
| EDGV | 841 | 190 |
| ... | ... | ... |
| YYYR | 203 | 1 |
| YYYS | 186 | 3 |
| YYYT | 181 | 14 |
| YYYW | 30 | 1 |
| YYYY | 57 | 2 |
149361 rows × 2 columns
We first filter sequences that are poorly represented in the input library (<20 sequencing counts).
[23]:
counts = counts.loc[counts['input'] >= 20, :]
counts
[23]:
| input | selected | |
|---|---|---|
| sequence | ||
| VDGV | 92735 | 338346 |
| ADGV | 34 | 43 |
| CDGV | 850 | 641 |
| DDGV | 63 | 63 |
| EDGV | 841 | 190 |
| ... | ... | ... |
| YYYR | 203 | 1 |
| YYYS | 186 | 3 |
| YYYT | 181 | 14 |
| YYYW | 30 | 1 |
| YYYY | 57 | 2 |
142820 rows × 2 columns
And use Enrich2 approach to derive the enrichment score and the associated error.
[24]:
wt = 'VDGV'
c_wt_input, c_wt_sel = counts.loc[wt]
X = counts.index.values
y = (np.log((counts['selected'] + 0.5)/(c_wt_sel + 0.5)) - np.log((counts['input'] + 0.5)/(c_wt_input + 0.5))).values
y_var = (1/(counts['input'] + 0.5) + 1/(counts['selected'] + 0.5) + 1/(c_wt_sel + 0.5) + 1/(c_wt_input + 0.5)).values
data = pd.DataFrame({'y': y, 'y_var': y_var}, index=X)
To be able to evaluate model performance, we first split the data into training and test sets keeping approximately 90% of the data for training and 10% for testing
[25]:
u = np.random.uniform(size=y.shape[0]) < 0.9
X_train, y_train, y_var_train = X[u], y[u], y_var[u]
X_test, y_test = X[~u], y[~u]
Computing the minumum epistasis interpolation solution
[26]:
model = MinimumEpistasisInterpolator(P=2, seq_length=4, alphabet_type='protein')
model.set_data(X_train, y_train)
mei = model.predict()
mei
[26]:
| f | |
|---|---|
| AAAA | 0.460831 |
| AAAC | -2.478059 |
| AAAD | -3.579738 |
| AAAE | -4.836451 |
| AAAF | -3.947928 |
| ... | ... |
| YYYS | -5.269987 |
| YYYT | -3.821426 |
| YYYV | -3.143536 |
| YYYW | -4.306581 |
| YYYY | -4.429813 |
160000 rows × 1 columns
[27]:
lim = (-9, 3)
r2 = pearsonr(mei.loc[X_test, 'f'], y_test)[0] ** 2
bins = np.linspace(lim[0] + 0.5, lim[1] - 0.5, 100)
fig, axes = plt.subplots(1, 1, figsize=(4, 4))
axes.hist2d(x=mei.loc[X_test, 'f'], y=y_test, cmap="binary", bins=bins)
axes.axline((0, 0), (1, 1), lw=0.5, linestyle="--", c="grey")
axes.set(
xlabel=r"$y_{pred}$",
ylabel=r"$y_{obs}$",
xlim=(lim[0] + 0.5, lim[1] - 0.5),
ylim=(lim[0] + 0.5, lim[1] - 0.5),
)
axes.text(
0.05,
0.95,
r"$R^2$=" + "{:.3f}".format(r2),
transform=axes.transAxes,
color="black",
ha="left",
va="top",
)
[27]:
Text(0.05, 0.95, '$R^2$=0.833')
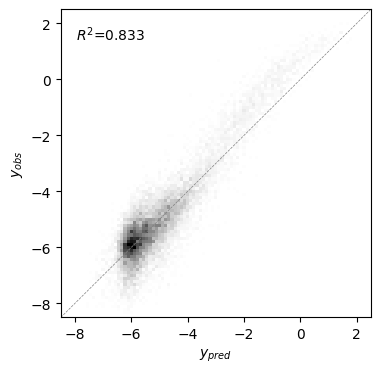
Estimating Variance Components
[28]:
model = VCregression(seq_length=4, alphabet_type='protein')
model.fit(X=X_train, y=y_train, y_var=y_var_train)
[29]:
lambdas = model.lambdas
x = np.arange(0, lambdas.shape[0])
variance = model.lambdas_to_variance(lambdas)
p_variance = variance / variance.sum() * 100
[30]:
fig, subplots = init_fig(1, 2, colsize=3.5, rowsize=3.5)
axes = subplots[0]
axes.bar(x=x, height=lambdas, color='black')
axes.set(xlabel='$k$', ylabel='$\lambda_k$', yscale='log')
axes = subplots[1]
axes.bar(x=x[1:], height=p_variance, color='black')
axes.set(xlabel='$k$', ylabel='% variance explained', ylim=(0, 100), xticks=[1, 2, 3])
fig.tight_layout()
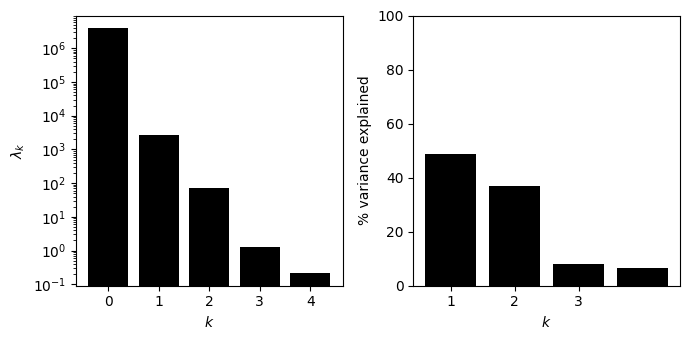
Inferring the complete GB1 landscape
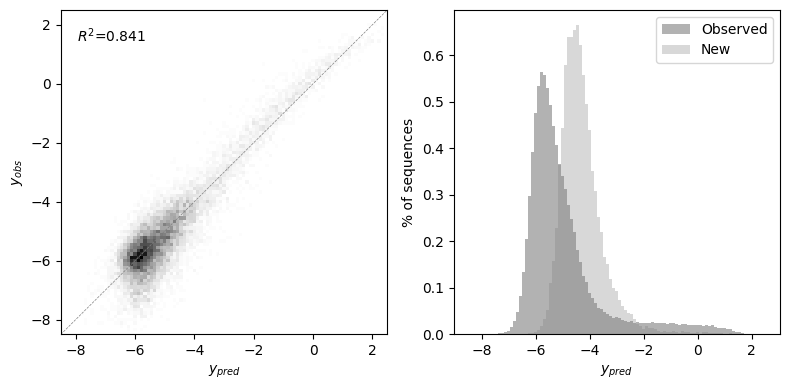
Now that we have inferred the variance components, we obtain inferences for the complete combinatorial landscape and check the prediction accuracy for the held-out test data. Moreover, we can also see the distribution of phenotypic values within and outside the data
[31]:
pred = model.predict().join(data)
pred
[31]:
| f | y | y_var | |
|---|---|---|---|
| AAAA | 0.632888 | 0.460831 | 0.046009 |
| AAAC | -2.361377 | NaN | NaN |
| AAAD | -3.231004 | NaN | NaN |
| AAAE | -4.600692 | NaN | NaN |
| AAAF | -3.443787 | NaN | NaN |
| ... | ... | ... | ... |
| YYYS | -4.954946 | -5.269987 | 0.291090 |
| YYYT | -3.854892 | -3.821426 | 0.074489 |
| YYYV | -3.438228 | -3.143536 | 0.074682 |
| YYYW | -4.949506 | -4.306581 | 0.699467 |
| YYYY | -5.092643 | -4.429813 | 0.417405 |
160000 rows × 3 columns
[32]:
test = pred.loc[X_test, :]
r2 = pearsonr(test['f'], test['y'])[0] ** 2
lim = (-9, 3)
bins = np.linspace(lim[0] + 0.5, lim[1] - 0.5, 100)
fig, subplots = plt.subplots(1, 2, figsize=(8, 4))
axes = subplots[0]
axes.hist2d(x=test['f'], y=test['y'], cmap='binary', bins=bins)
axes.axline((0, 0), (1, 1), lw=0.5, linestyle='--', c='grey')
axes.set(xlabel=r'$y_{pred}$', ylabel=r'$y_{obs}$',
xlim=(lim[0] + 0.5, lim[1] - 0.5),
ylim=(lim[0] + 0.5, lim[1] - 0.5))
axes.text(0.05, 0.95, r'$R^2$=' + '{:.3f}'.format(r2),
transform=axes.transAxes, color='black', ha='left', va='top')
axes = subplots[1]
axes.hist(pred.dropna()['f'], label='Observed', alpha=0.3, density=True, bins=bins, color='black')
axes.hist(pred.loc[np.isnan(pred['y']), 'f'], label='New', alpha=0.3, density=True, bins=bins, color='grey')
axes.set(xlabel=r'$y_{pred}$', ylabel='% of sequences')
axes.legend(loc=0)
fig.tight_layout()
Estimating local epistatic coefficients under the prior
As previously shown, we are not only restricted to making calibrated predictions for previously uncharacterized or held out sequences, but we can also get calibrated estimates for linear combinations of them and use them to answer questions about specific mutational effects and how they change as we introduced more mutations.
One of the main interactions in the GB1 dataset is that taking place between positions 41 and 54. In the wild-type sequence VDGV, G41L is highly deleterious, but becomes advantageous in the presence of V54G. Now, we can use our model to compute the posterior distribution for this epistatic coefficient given the whole dataset.
We can select the 4 relevant sequences and show their measurement values
[33]:
seqs = ['VDGV', 'VDGG', 'VDLV', 'VDLG']
df = data.loc[seqs, :]
df
[33]:
| y | y_var | |
|---|---|---|
| VDGV | 0.000000 | 0.000027 |
| VDGG | 0.334153 | 0.003038 |
| VDLV | -3.512487 | 0.105615 |
| VDLG | 1.140357 | 0.013197 |
We then define the contrast matrices for the coefficients of interest: the single point mutational effects as well as the epistatic coefficient between them.
[34]:
contrast_matrix = pd.DataFrame({'G41L' : [-1, 0, 1, 0],
'V54G' : [-1, 1, 0, 0],
'G41L:V54G': [ 1, -1, -1, 1]},
index=seqs)
contrast = model.make_contrasts(contrast_matrix)
contrast
100%|██████████| 3/3 [01:08<00:00, 23.00s/it]
[34]:
| estimate | std | ci_95_lower | ci_95_upper | p(|x|>0) | |
|---|---|---|---|---|---|
| G41L | -3.497472 | 0.276578 | -4.050627 | -2.944317 | 1.000000 |
| V54G | -1.094177 | 0.515773 | -2.125724 | -0.062630 | 0.983057 |
| G41L:V54G | 5.739408 | 0.593206 | 4.552996 | 6.925820 | 1.000000 |
We can see that there is strong support in the posterior for the deleterious effect of G41L in the wild-type background, but also that this is strongly reversed in the presence of V54G. Lets now compare these estimates with the naive comparisons using the estimated measurement errors alone
[35]:
make_contrasts(df, contrast_matrix)
[35]:
| estimate | std | ci_95_lower | ci_95_upper | p(|x|>0) | |
|---|---|---|---|---|---|
| G41L | -3.512487 | 0.325026 | -4.162539 | -2.862435 | 1.0 |
| V54G | 0.334153 | 0.055370 | 0.223413 | 0.444892 | 1.0 |
| G41L:V54G | 4.318691 | 0.349109 | 3.620472 | 5.016910 | 1.0 |
We can see how estimates are then shrunk towards 0 and uncertaintly is slightly reduced by using the prior that was estimated across the complete dataset
Inference from real data: the Shine-Dalgarno sequence
In this section, we will show how to use MinimumEpistasisInterpolator and VCregression to infer and analyze the genotype-phenotype map of the Shine-Dalgarno (SD) sequence. We use data from a high-throuhgput experimental Sort-Seq assay in which translational efficiency of a library of about 250,000 9-nucleotide sequences was measured (Kuo et al. 2020) as in our original gpmap-tools paper (Martí-Gómez et
al. 2025). For full reproducibility of the analysis of the Shine-Dalgarno landscape, including processing of the raw data, see the associated repository.
Loading high-throughput measurements
Here, for simplicity, we use the built-in dataset provided by gpmap-tools for the Shine-Dalgarno sequence as over 250,000 measured 9-nucleotide sequences with the associated noise estimates from the replicate experiments.
[ ]:
dmsc = DataSet('dmsc')
dmsc.data
| y | y_var | |
|---|---|---|
| Genotype | ||
| AAAAAAAAA | 0.563000 | 0.017082 |
| AAAAAAAAC | 0.664000 | 0.017082 |
| AAAAAAAAG | 0.643000 | 0.017082 |
| AAAAAAAAU | 0.654333 | 0.017082 |
| AAAAAAACA | 0.594667 | 0.017082 |
| ... | ... | ... |
| UUUUUUUGU | 0.705667 | 0.017082 |
| UUUUUUUUA | 0.590667 | 0.017082 |
| UUUUUUUUC | 0.551333 | 0.017082 |
| UUUUUUUUG | 0.523667 | 0.017082 |
| UUUUUUUUU | 0.538333 | 0.017082 |
257565 rows × 2 columns
First, we split the dataset into training and test sets to evaluate the performance of the different models
[ ]:
np.random.seed(0)
u = np.random.uniform(size=dmsc.data.shape[0])
train = dmsc.data.loc[u < 0.999, :]
test = dmsc.data.loc[u > 0.999, :]
X_train, y_train, y_var_train = train.index.values, train.y.values, train.y_var.values
X_test, y_test = test.index.values, test.y.values
Minimum epistasis interpolation
Now we fit a model using the training data and make predictions for the complete sequence-space
[ ]:
model = MinimumEpistasisInterpolator(P=2, seq_length=9, alphabet_type='rna')
model.fit(X_train, y_train)
mei = model.predict()
mei
| f | |
|---|---|
| AAAAAAAAA | 0.563000 |
| AAAAAAAAC | 0.664000 |
| AAAAAAAAG | 0.643000 |
| AAAAAAAAU | 0.654333 |
| AAAAAAACA | 0.594667 |
| ... | ... |
| UUUUUUUGU | 0.705667 |
| UUUUUUUUA | 0.590667 |
| UUUUUUUUC | 0.551333 |
| UUUUUUUUG | 0.523667 |
| UUUUUUUUU | 0.538333 |
262144 rows × 1 columns
We can now also compute the predictive uncertainty under the model with the minimum amount of epistasis for a few sequences of interest. Lets try with the test sequences
[ ]:
pred = model.predict(X_pred=X_test, calc_variance=True)
100%|██████████| 274/274 [00:20<00:00, 13.41it/s]
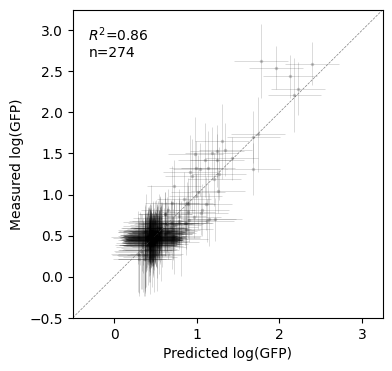
Lets now see how similar the predictions are to the measurements in these held-out sequences
[ ]:
test_mei = test.join(pred, rsuffix="_pred")
fig, axes = plt.subplots(1, 1, figsize=(4, 4))
x, xerr = test_mei["f"], 2 * test_mei["f_std"]
y, yerr = test_mei["y"], 2 * np.sqrt(test_mei["y_var"])
lims = (-0.5, 3.25)
r2 = pearsonr(y, x)[0] ** 2
axes.errorbar(
x,
y,
xerr=xerr,
yerr=yerr,
color="black",
fmt="o",
alpha=0.2,
markeredgewidth=0,
markersize=2.5,
lw=0.5,
)
axes.set(
xlim=lims,
ylim=lims,
xticks=np.arange(4),
xlabel="Predicted log(GFP)",
ylabel="Measured log(GFP)",
)
axes.axline((0, 0), (1, 1), lw=0.5, c="grey", linestyle="--")
axes.text(
0.05,
0.95,
"$R^2$" + "={:.2f}\nn={}".format(r2, test_mei.shape[0]),
transform=axes.transAxes,
va="top",
ha="left",
)
Text(0.05, 0.95, '$R^2$=0.86\nn=274')
Estimating Variance Components
We next use VCregression to better understand the complexity of genetic interactions and achieve more accurate and calibrated phenotypic predictions. We first estimate the variance components of a prior under which the expected distance-covariance function matches as best as possible the observed one in the empirical data.
[ ]:
model = VCregression(seq_length=4, alphabet_type='protein')
model.fit(X=X_train, y=y_train, y_var=y_var_train)
We can easily extract the inferred variance components
[ ]:
prior_vc = model.get_variance_components()
prior_vc
| k | lambdas | var_perc | var_perc_cum | |
|---|---|---|---|---|
| 0 | 0 | 98904.042381 | 0.000000 | 0.000000 |
| 1 | 1 | 373.777526 | 34.797093 | 34.797093 |
| 2 | 2 | 20.420498 | 22.812735 | 57.609829 |
| 3 | 3 | 2.527750 | 19.767108 | 77.376937 |
| 4 | 4 | 0.287375 | 10.112773 | 87.489710 |
| 5 | 5 | 0.050127 | 5.291929 | 92.781639 |
| 6 | 6 | 0.016396 | 3.461801 | 96.243440 |
| 7 | 7 | 0.008550 | 2.321172 | 98.564612 |
| 8 | 8 | 0.005602 | 1.140652 | 99.705264 |
| 9 | 9 | 0.004343 | 0.294736 | 100.000000 |
[ ]:
fig, subplots = plt.subplots(1, 2, figsize=(6.5, 3))
axes = subplots[0]
axes.scatter(prior_vc["k"], prior_vc["lambdas"], color="black")
axes.plot(prior_vc["k"], prior_vc["lambdas"], color="black")
axes.set(xlabel="$k$", ylabel="$\lambda_k$", yscale="log", xticks=prior_vc['k'])
# Plot percentage variance explained
vcs = prior_vc.loc[prior_vc['k'] > 0, :]
axes = subplots[1]
axes.bar(x=vcs["k"], height=vcs["var_perc"], color="black")
axes.set(
xlabel="Interaction order $k$",
ylabel="% variance explained",
xticks=np.arange(1, 10),
ylim=(0, 50),
)
# Plot cumulative percentage variance explained
axes = axes.twinx()
axes.scatter(vcs["k"], vcs["var_perc_cum"], color="grey", s=25)
axes.plot(vcs["k"], vcs["var_perc_cum"], color="grey", lw=2)
axes.tick_params(axis="y", colors="grey")
axes.spines["right"].set_color("grey")
axes.set(ylim=(0, 105))
axes.set_ylabel("% cumulative variance", color="grey")
fig.tight_layout()
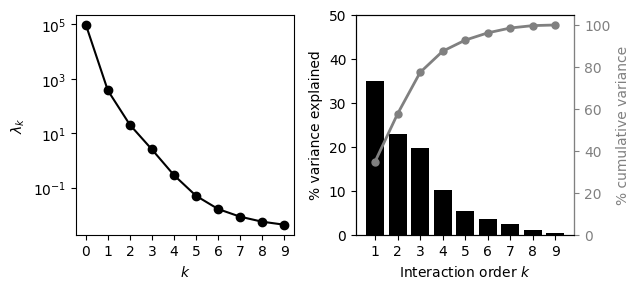
We can see that the inferred \(\lambda_k\) monotonically decrease with the interaction order \(k\), and that the decay is slower than exponential. Moreover, the second plot showing the total variance explained by interactions of every possible order \(k\) and cumulative variance explained by interactions up to order \(k\) suggests a large contribution of higher order epistatic interactions (\(k>2\)) to the genotype-phenotype map of the SD sequence.
Inference with VCregression
We next infer the complete combinatorial landscape under the inferred variance component prior distribution using VCregression
[ ]:
pred = model.predict()
pred
| f | |
|---|---|
| AAAAAAAAA | 0.563857 |
| AAAAAAAAC | 0.701509 |
| AAAAAAAAG | 0.619187 |
| AAAAAAAAU | 0.628770 |
| AAAAAAACA | 0.594684 |
| ... | ... |
| UUUUUUUGU | 0.615908 |
| UUUUUUUUA | 0.539057 |
| UUUUUUUUC | 0.548780 |
| UUUUUUUUG | 0.536609 |
| UUUUUUUUU | 0.564958 |
262144 rows × 1 columns
and compute the posterior distribution for the same test sequences as before
[ ]:
pred = model.predict(X_pred=X_test, calc_variance=True)
100%|██████████| 274/274 [35:43<00:00, 7.82s/it]
[ ]:
test_vc = test.join(pred, rsuffix="_pred")
fig, axes = plt.subplots(1, 1, figsize=(4, 4))
x, xerr = test_vc["f"], 2 * test_vc["f_std"]
y, yerr = test_vc["y"], 2 * np.sqrt(test_vc["y_var"])
lims = (-0.5, 3.25)
r2 = pearsonr(y, x)[0] ** 2
axes.errorbar(
x,
y,
xerr=xerr,
yerr=yerr,
color="black",
fmt="o",
alpha=0.2,
markeredgewidth=0,
markersize=2.5,
lw=0.5,
)
axes.set(
xlim=lims,
ylim=lims,
xticks=np.arange(4),
xlabel="Predicted log(GFP)",
ylabel="Measured log(GFP)",
)
axes.axline((0, 0), (1, 1), lw=0.5, c="grey", linestyle="--")
axes.text(
0.05,
0.95,
"$R^2$" + "={:.2f}\nn={}".format(r2, test_vc.shape[0]),
transform=axes.transAxes,
va="top",
ha="left",
)
Text(0.05, 0.95, '$R^2$=0.87\nn=274')
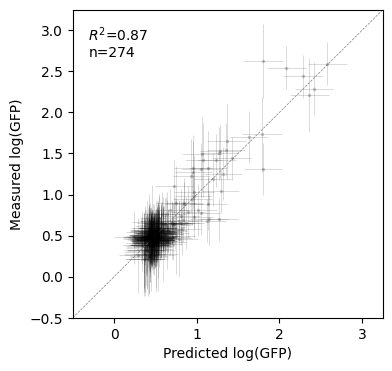
fitting VCregression is substantially slower because of the higher expressivity of the prior distribution. In this particular case, we have measurements over a large fraction of all possible sequences, the performance of both VCregression and MinimumEpistasisInterpolator are very similar when evaluated on the same test set.
Estimating context-dependent mutational effects
In addition to computing the posterior distribution for a specific subset of sequences, gpmap-tools also enables the computation of the posterior distribution of any possible linear combination of phenotypes. This can be used, for instance, to compute the posterior distribution for the effects of a series of mutations in different genetic backgrounds. In this case, we wanted to test the effects of mutations in two genetic backgrounds 'UUAAGGAGC' and 'UAAGGAGCA', characterized by
having an AGGAG motif at adjacent positions in the sequence.
To do this, as in any linear model, we need to define a contrast matrix, with a series of sequences on the rows and the specified contrasts on the columns.
[ ]:
backgrounds = ["UUAAGGAGC", "UAAGGAGCA"]
positions = np.arange(-13, -4)
contrasts = {}
for bc1, bc2 in combinations(backgrounds, 2):
for p, (pos, a1, a2) in enumerate(zip(positions, bc1, bc2)):
if a1 == a2:
continue
label = "{}{}{}".format(a1, pos, a2)
for bc in [bc1, bc2]:
s = [c for c in bc]
s[p] = a1
s1 = "".join(s)
s[p] = a2
s2 = "".join(s)
contrasts["{}_in_{}".format(label, bc)] = {s1: -1, s2: 1}
contrasts_matrix = pd.DataFrame(contrasts).fillna(0)
contrasts_matrix
| U-12A_in_UUAAGGAGC | U-12A_in_UAAGGAGCA | A-10G_in_UUAAGGAGC | A-10G_in_UAAGGAGCA | G-8A_in_UUAAGGAGC | G-8A_in_UAAGGAGCA | A-7G_in_UUAAGGAGC | A-7G_in_UAAGGAGCA | G-6C_in_UUAAGGAGC | G-6C_in_UAAGGAGCA | C-5A_in_UUAAGGAGC | C-5A_in_UAAGGAGCA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UUAAGGAGC | -1.0 | 0.0 | -1.0 | 0.0 | -1.0 | 0.0 | -1.0 | 0.0 | -1.0 | 0.0 | -1.0 | 0.0 |
| UAAAGGAGC | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| UUAGGAGCA | 0.0 | -1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| UAAGGAGCA | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 |
| UUAGGGAGC | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| UAAAGAGCA | 0.0 | 0.0 | 0.0 | -1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| UUAAGAAGC | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| UAAGGGGCA | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| UUAAGGGGC | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| UAAGGAACA | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| UUAAGGACC | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| UAAGGAGGA | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | 0.0 | 0.0 |
| UUAAGGAGA | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| UAAGGAGCC | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 |
[ ]:
mut_eff_contrasts = model.make_contrasts(contrasts_matrix)
100%|██████████| 12/12 [03:28<00:00, 17.36s/it]
[ ]:
items = [x.split("_") for x in mut_eff_contrasts.index.values]
mut_eff_contrasts["mutation"] = [x[0] for x in items]
mut_eff_contrasts["background"] = [x[-1] for x in items]
mut_eff_contrasts
| estimate | std | ci_95_lower | ci_95_upper | p(|x|>0) | mutation | background | |
|---|---|---|---|---|---|---|---|
| U-12A_in_UUAAGGAGC | 0.036403 | 0.120603 | -0.204802 | 0.277608 | 0.618614 | U-12A | UUAAGGAGC |
| U-12A_in_UAAGGAGCA | 0.439055 | 0.120575 | 0.197905 | 0.680204 | 0.999864 | U-12A | UAAGGAGCA |
| A-10G_in_UUAAGGAGC | -1.296304 | 0.125055 | -1.546413 | -1.046195 | 1.000000 | A-10G | UUAAGGAGC |
| A-10G_in_UAAGGAGCA | 1.868371 | 0.124346 | 1.619680 | 2.117063 | 1.000000 | A-10G | UAAGGAGCA |
| G-8A_in_UUAAGGAGC | -1.635327 | 0.124599 | -1.884525 | -1.386129 | 1.000000 | G-8A | UUAAGGAGC |
| G-8A_in_UAAGGAGCA | 1.837495 | 0.120470 | 1.596555 | 2.078435 | 1.000000 | G-8A | UAAGGAGCA |
| A-7G_in_UUAAGGAGC | -1.434428 | 0.120734 | -1.675896 | -1.192960 | 1.000000 | A-7G | UUAAGGAGC |
| A-7G_in_UAAGGAGCA | 0.767023 | 0.130634 | 0.505756 | 1.028291 | 1.000000 | A-7G | UAAGGAGCA |
| G-6C_in_UUAAGGAGC | -1.465185 | 0.124660 | -1.714505 | -1.215864 | 1.000000 | G-6C | UUAAGGAGC |
| G-6C_in_UAAGGAGCA | -0.602313 | 0.139946 | -0.882205 | -0.322421 | 0.999992 | G-6C | UAAGGAGCA |
| C-5A_in_UUAAGGAGC | 0.427133 | 0.125927 | 0.175280 | 0.678986 | 0.999653 | C-5A | UUAAGGAGC |
| C-5A_in_UAAGGAGCA | 0.360164 | 0.125318 | 0.109528 | 0.610801 | 0.997973 | C-5A | UAAGGAGCA |
while we can already see the differences in the effects of mutations across the two genetic backgrounds in the table, we can also plot these posterior distributions
[ ]:
fig, axes = plt.subplots(1, 1, figsize=(4, 1.5))
palette = dict(zip(backgrounds, ['grey', 'black']))
dx = dict(zip(backgrounds, [-0.125, 0.125]))
kwargs = {
"fmt": "o",
"lw": 0,
"elinewidth": 2,
"capsize": 3,
"markersize": 5,
}
for background, df in mut_eff_contrasts.groupby('background'):
df["x"] = np.arange(df.shape[0]) - 0.125
axes.errorbar(
df["x"] + dx[background],
df["estimate"],
yerr=2 * df["std"],
color=palette[background],
label=background,
**kwargs,
)
axes.set(
xlabel="Mutation",
ylabel="$\Delta$log(GFP)",
xticks=df["x"],
xticklabels=df["mutation"],
)
axes.axhline(0, linestyle="--", c="grey", lw=0.75)
axes.legend(loc=(0.02, 1.025), ncol=2)
<matplotlib.legend.Legend at 0x7fb0cb387fd0>
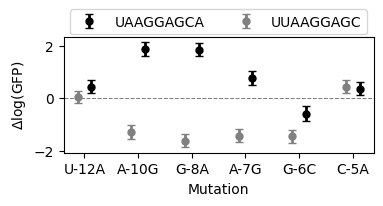
Estimating average phenotype across genetic backgrounds
In some cases, when measurements are not accurate enough, it is hard to draw solid conclusions about the phenotypes or mutational effects at specific sequences. However, we can often reliably estimate the average across a series of genetic backgrounds that we believe behave in the same manner. For instance, in the SD sequence, we hypothesized that we can obtain functional sequences by having at least one of two overlapping AGGAG motifs but that only a partial AGG match would be insufficient to drive high translationa efficiency.
To investigate this question, we define a contrast matrix to compute these average phenotypes across uniformly sampled genetic backgrounds, and compare it with the wild-type sequence 'AAGGAGGUG' and the average of all possible sequences 'NNNNNNNNN'.
[ ]:
bc1 = np.array(["".join(x) for x in product("ACGU", repeat=3)])
bc2 = np.array(["".join(x) for x in product("ACGU", repeat=6)])
bc3 = np.array(["".join(x) for x in product("ACGU", repeat=9)])
bc4 = np.array(["".join(x) for x in product("ACGU", repeat=2)])
p1, p2, p3 = 1.0 / bc1.shape[0], 1.0 / bc2.shape[0], 1.0 / bc3.shape[0]
p4 = 1.0 / bc4.shape[0]
contrasts = {
"AGGAGGNNN": {"AGGAGG{}".format(x): p1 for x in bc1},
"NGGAGGAGN": {"{}GGAGGAG{}".format(x[0], x[-1]): p4 for x in bc4},
"NNNAGGNNN": {"{}AGG{}".format(x[:3], x[3:]): p2 for x in bc2},
"NNNAGGAGG": {"{}AGGAGG".format(x): p1 for x in bc1},
"AAGGAGGUG": {"AAGGAGGUG": 1.0},
"NNNNNNNNN": {x: p3 for x in bc3},
}
contrast_matrix = pd.DataFrame(contrasts).fillna(0)
[ ]:
avg_phenotypes_contrasts = model.make_contrasts(contrast_matrix)
100%|██████████| 6/6 [00:26<00:00, 4.39s/it]
[ ]:
avg_phenotypes_contrasts
| estimate | std | ci_95_lower | ci_95_upper | p(|x|>0) | |
|---|---|---|---|---|---|
| AGGAGGNNN | 2.389234 | 0.019362 | 2.350510 | 2.427958 | 1.0 |
| NGGAGGAGN | 2.769155 | 0.039200 | 2.690755 | 2.847554 | 1.0 |
| NNNAGGNNN | 1.026140 | 0.003014 | 1.020112 | 1.032169 | 1.0 |
| NNNAGGAGG | 2.473923 | 0.020875 | 2.432174 | 2.515673 | 1.0 |
| AAGGAGGUG | 2.026292 | 0.085422 | 1.855448 | 2.197137 | 1.0 |
| NNNNNNNNN | 0.620093 | 0.000485 | 0.619123 | 0.621064 | 1.0 |
[ ]:
fig, axes = plt.subplots(1, 1, figsize=(2, 1.5))
seqs = ["AGGAGGNNN", "NGGAGGAGN", "NNNAGGNNN", "NNNAGGAGG"]
labels = [
r"$\bf{AGGAGG}$NNN",
r"N$\bf{GGAGGAG}$N",
r"NNN$\bf{AGG}$NNN",
r"NNN$\bf{AGGAGG}$",
]
df = avg_phenotypes_contrasts.loc[seqs, :].copy()
df["step"] = np.arange(1, df.shape[0] + 1)
kwargs = {
"fmt": "o",
"lw": 0,
"elinewidth": 2,
"capsize": 3,
"markersize": 2,
}
axes.errorbar(
df["step"],
df["estimate"],
yerr=2 * df["std"],
color='black',
**kwargs,
)
axes.set(
xlabel="Genetic background",
ylabel="log(GFP)",
xticks=df["step"],
xlim=(0.5, 4.5),
)
axes.set_xticklabels(labels, rotation=45, ha="right")
for s in ['NNNNNNNNN', 'AAGGAGGUG']:
axes.axhline(
avg_phenotypes_contrasts.loc[s, "estimate"],
linestyle="--",
c="grey",
lw=0.75,
label="Average",
)
axes.axhspan(
ymin=avg_phenotypes_contrasts.loc[s, "ci_95_lower"],
ymax=avg_phenotypes_contrasts.loc[s, "ci_95_upper"],
color="grey",
alpha=0.3,
lw=0,
)
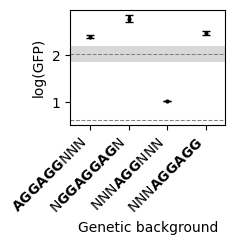
Here, we see that by averaging across genetic backgrounds, our uncertaintly about average phenotypes is very small, as shown by the posterior standard deviation. Moreover, these results clearly show that having an AGG triplet, is in general insufficient for inducing efficient translation initiation, as opposed to having either one or two overlapping binding sites.